


The Complete Guide to Robots.txt: Best Practices and Common Mistakes to Avoid

What Is A Robots.txt File?
A robots.txt file acts as a guide for search engine crawlers, such as Googlebot and Bingbot, by providing instructions on how to navigate and index your site. Think of it like a map at the entrance of a museum, showing visitors what can and can’t be explored. It includes information like:
- Which crawlers are allowed or blocked from accessing certain parts of the site.
- Specific pages or sections that should not be crawled.
- Priority pages for crawling, often highlighted through the XML sitemap.
The main purpose of the robots.txt file is to manage crawler access by marking certain areas of your website as off-limits. This helps ensure crawlers focus their resources on the most important content, rather than wasting crawl budget on less valuable pages.
Although the robots.txt file is an effective guide for search engines, it's important to note that not all bots follow its rules, especially malicious ones. However, reputable search engines typically respect the directives set in the file.
What Is Included In A Robots.txt File?
A robots.txt file is made up of lines of directives that instruct search engine crawlers and other bots on how to interact with a website.
Each valid line in the file follows a simple structure: a field, followed by a colon, and then a value.
To enhance readability, robots.txt files often include blank lines and comments, allowing website owners to organize and track the directives more easily.

To understand the typical contents of a robots.txt file and how different websites use it, I analyzed the robots.txt files of 60 high-traffic domains from various industries, including healthcare, financial services, retail, and high-tech. After excluding comments and blank lines, the average length of these files was 152 lines.
Larger publishers and aggregators, such as hotels.com, forbes.com, and nytimes.com, typically had longer files, while healthcare sites like pennmedicine.org and hopkinsmedicine.com had shorter ones. Retailers' robots.txt files generally matched the 152-line average.
Every site in the study included the "user-agent" and "disallow" directives in their robots.txt files, and 77% also featured a sitemap declaration using the "sitemap" field. Less frequently used directives included "allow" (present in 60% of sites) and "crawl-delay" (used by 20% of sites).
Robots.txt Syntax
Now that we’ve explored the common fields found in a robots.txt file, let’s take a closer look at the meaning and proper usage of each one.
For detailed information on robots.txt syntax and how Google interprets it, be sure to check out Google’s official robots.txt documentation.
User-Agent
The user-agent field defines which crawler the directives (such as disallow or allow) apply to. You can use this field to target specific bots or crawlers, or use a wildcard to apply the rules universally.
For example, the following syntax applies the directives solely to Googlebot:
user-agent: GooglebotIf you want the rules to apply to all crawlers, simply use the wildcard:
user-agent: *You can also include multiple user-agent fields in your robots.txt file to specify different rules for different crawlers or groups of crawlers. For instance:
user-agent: *
# These rules apply to all crawlers
user-agent: Googlebot
# These rules apply only to Googlebot
user-agent: otherbot1
user-agent: otherbot2
user-agent: otherbot3
# These rules apply to otherbot1, otherbot2, and otherbot3Disallow And Allow
The disallow field defines the paths that designated crawlers should avoid, while the allow field specifies the paths they are permitted to access.
Since crawlers like Googlebot assume they can access URLs that aren’t explicitly disallowed, many websites choose to keep it simple and only use the disallow field to block specific paths.
For example, the following syntax tells all crawlers not to access URLs with the path /do-not-enter:
user-agent: *
disallow: /do-not-enterIn cases of conflicting rules, Google tends to prioritize the more specific directive. For instance:
user-agent: *
allow: /
disallow: /do-not-enterIn this case, Googlebot would not crawl /do-not-enter because the disallow rule is more specific than the allow rule.
On the other hand, if the rules are equally specific, Google will default to the less restrictive one. For example:
user-agent: *
allow: /do-not-enter
disallow: /do-not-enterHere, Googlebot would crawl /do-not-enter because the allow rule takes precedence over the disallow rule.
If no path is specified after allow or disallow, the rule is ignored:
user-agent: *
disallow:This is different from specifying just a forward slash (/), which would block crawlers from accessing every page on your site. For instance, the following would prevent search engines from crawling any of your pages:
user-agent: *
disallow: /Make sure you avoid this mistake, as it can block your entire website from search engine crawlers!
If you're using both allow and disallow fields in your robots.txt file, it’s important to refer to Google’s documentation on the order of precedence for rules to ensure you’re implementing them correctly.
URL Paths
URL paths are the part of the URL that comes after the protocol, subdomain, and domain, starting with a forward slash (/). For example, in the URL https://www.example.com/guides/technical/robots-txt, the path would be /guides/technical/robots-txt.

URL paths are case-sensitive, so be sure to double-check that the use of capitals and lower cases in the robot.txt aligns with the intended URL path.
Special Characters
Google, Bing, and other major search engines support a limited set of special characters to match URL paths more effectively.
Special characters are symbols with specific meanings that go beyond just representing regular letters or numbers. The following special characters are supported by Google in robots.txt files:
- Asterisk (*) – matches zero or more instances of any character.
- Dollar sign ($) – indicates the end of the URL.
To illustrate how these special characters work, consider the following URLs from a small website:
- https://www.example.com/
- https://www.example.com/search
- https://www.example.com/guides
- https://www.example.com/guides/technical
- https://www.example.com/guides/technical/robots-txt
- https://www.example.com/guides/technical/robots-txt.pdf
- https://www.example.com/guides/technical/xml-sitemaps
- https://www.example.com/guides/technical/xml-sitemaps.pdf
- https://www.example.com/guides/content
- https://www.example.com/guides/content/on-page-optimization
- https://www.example.com/guides/content/on-page-optimization.pdf
1: Block Site Search Results
A common use of robots.txt is to block internal site search results, as these pages generally don’t provide significant value for organic search.
For example, when users search on https://www.example.com/search, their query is appended to the URL. If someone searches for "xml sitemap guide," the URL for the search results page would be https://www.example.com/search?search-query=xml-sitemap-guide.
When specifying a URL path in robots.txt, it matches any URLs containing that path, not just the exact URL. So, to block both the base search URL and the search results URL, you don’t need to use a wildcard.
The following rule would block both https://www.example.com/search and https://www.example.com/search?search-query=xml-sitemap-guide:
user-agent: *
disallow: /searchThis rule prevents all crawlers from accessing any page with the /search path.
If you were to add a wildcard (*), the result would still be the same. For example:
user-agent: *
disallow: /search*This would also block URLs like https://www.example.com/search?search-query=xml-sitemap-guide.
Example Scenario 2: Block PDF files
In some cases, you may want to block specific types of files using the robots.txt file.
For example, if the site creates PDF versions of its guides for user convenience, this could result in two URLs with identical content. The site owner may want to prevent search engines from crawling the PDF versions.
In this case, a wildcard (*) can be used to match any URLs where the path starts with /guides/ and ends with .pdf, with varying characters in between.
user-agent: *
disallow: /guides/*.pdfThis rule would block search engines from crawling any URLs that fit the pattern, such as:
- https://www.example.com/guides/technical/robots-txt.pdf
- https://www.example.com/guides/technical/xml-sitemaps.pdf
- https://www.example.com/guides/content/on-page-optimization.pdf
Example Scenario 3: Block Category Pages
In this example, suppose the site created category pages for technical and content guides to help users navigate content more easily in the future. However, with only three guides published, these category pages aren't providing much value to users or search engines.
The site owner might want to temporarily prevent search engines from crawling the category pages (e.g., https://www.example.com/guides/technical) while still allowing crawlers to index the individual guides within those categories (e.g., https://www.example.com/guides/technical/robots-txt).
To achieve this, we can use the "$" symbol to designate the end of the URL path.
user-agent: *
disallow: /guides/technical$
disallow: /guides/content$This rule would block crawlers from accessing:
But still allow crawlers to access:
- https://www.example.com/guides/technical/robots-txt
- https://www.example.com/guides/technical/xml-sitemaps
- https://www.example.com/guides/content/on-page-optimization
Sitemap
The sitemap field in a robots.txt file provides search engines with a direct link to one or more XML sitemaps.
While it's not mandatory, including XML sitemaps in your robots.txt file is considered a best practice. It helps search engines find and prioritize URLs to crawl.
The value of the sitemap field should be an absolute URL (e.g., https://www.example.com/sitemap.xml), not a relative URL (e.g., /sitemap.xml). If your site has multiple XML sitemaps, you can list each one with a separate sitemap field.
Here’s an example of a robots.txt file with a single XML sitemap:
user-agent: *
disallow: /do-not-enter
sitemap: https://www.example.com/sitemap.xmlAnd an example with multiple XML sitemaps:
user-agent: *
disallow: /do-not-enter
sitemap: https://www.example.com/sitemap-1.xml
sitemap: https://www.example.com/sitemap-2.xml
sitemap: https://www.example.com/sitemap-3.xmlCrawl-Delay
As noted earlier, 20% of sites include the crawl-delay field in their robots.txt file.
The crawl-delay field instructs bots on how much time they should wait between requests to prevent overloading the server.
The value for crawl-delay is expressed in seconds, indicating how long crawlers should pause before requesting the next page. For example, the following rule would instruct the specified crawler to wait five seconds between each request:
user-agent: FastCrawlingBot
crawl-delay: 5However, Google has clarified that it does not support the crawl-delay field, and it will ignore it. Other major search engines like Bing and Yahoo do respect crawl-delay directives.
| Search Engine | Primary User-Agent | Respects Crawl-Delay? |
|---|---|---|
| Googlebot | No | |
| Bing | Bingbot | Yes |
| Yahoo | Slurp | Yes |
| Yandex | YandexBot | Yes |
| Baidu | Baiduspider | No |
Crawl-delay directives are typically applied to all user agents (using user-agent: *), as well as to search engine crawlers that honor the crawl-delay field, and crawlers for SEO tools like Ahrefbot and SemrushBot.
The crawl-delay values observed ranged from one second to 20 seconds, with five and 10 seconds being the most common across the 60 sites analyzed.
Testing Robots.txt Files
Whenever you're creating or updating a robots.txt file, it's important to test the directives, syntax, and structure before publishing it.
The Robots.txt Validator and Testing Tool makes this process simple (thanks to Max Prin for this great resource!).
To test a live robots.txt file, simply:
- Add the URL you want to test.
- Select your user agent.
- Choose “live.”
- Click “test.”
The below example shows that Googlebot smartphone is allowed to crawl the tested URL.
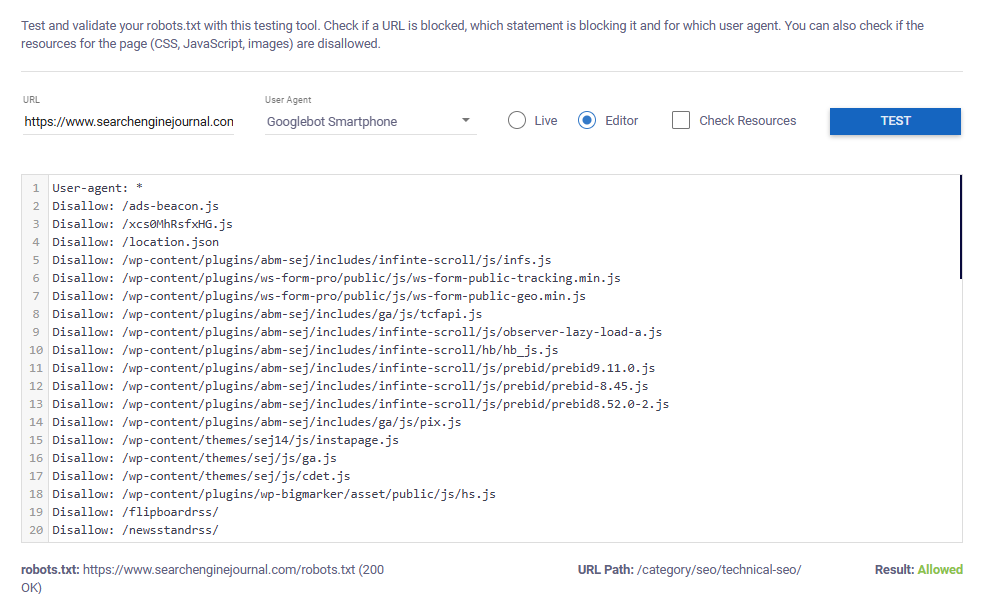
If the tested URL is blocked, the tool will highlight the specific rule that prevents the selected user agent from crawling it.
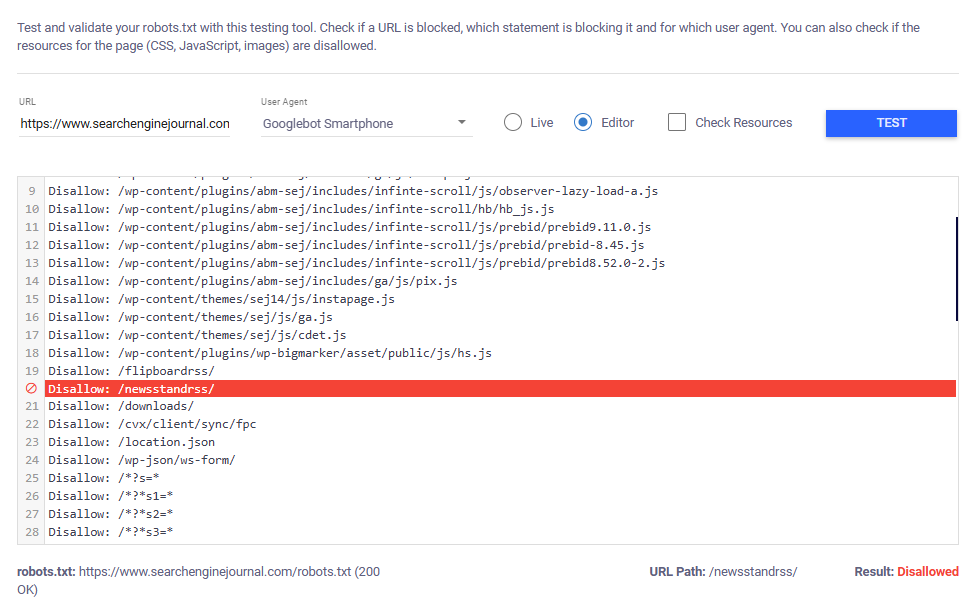
To test new rules before they are published, switch to “Editor” and paste your rules into the text box before testing.
Common Uses Of A Robots.txt File
Although the contents of a robots.txt file can vary significantly between websites, an analysis of 60 robots.txt files revealed common patterns in how it’s used and the types of content that webmasters typically block search engines from crawling.
Preventing Search Engines From Crawling Low-Value Content
Many websites, especially large ones like e-commerce or content-heavy platforms, generate "low-value pages" as a result of features designed to enhance the user experience.
For example, internal search pages and faceted navigation options (such as filters and sorting) help users quickly find what they're looking for. While these features are essential for usability, they can lead to duplicate or low-value URLs that don't contribute meaningfully to search rankings.
To address this, the robots.txt file is commonly used to block these pages from being crawled.
Here are some common types of content that are blocked via robots.txt:
- Parameterized URLs: URLs with tracking parameters, session IDs, or dynamic variables are blocked because they often lead to duplicate content, wasting crawl budget. Blocking these ensures that search engines focus on the primary, clean URL.
- Filters and Sorts: Filtered and sorted URLs (e.g., product pages sorted by price or filtered by category) are blocked to prevent the indexing of multiple versions of the same page, reducing duplicate content and helping search engines prioritize the most relevant version.
- Internal Search Results: Search result pages are often blocked as they may generate low-value content or duplicate content, and in some cases, could lead to inappropriate, user-generated content being indexed.
- User Profiles: Profile pages may be blocked to protect user privacy, minimize low-value pages being crawled, and focus on more important content like product pages or blog posts.
- Testing, Staging, or Development Environments: These non-public environments are blocked to prevent them from being crawled and indexed by search engines.
- Campaign Sub-folders: Landing pages for specific marketing campaigns, such as direct mail landing pages, may be blocked if they are not intended for general search audience visibility.
- Checkout and Confirmation Pages: Blocking checkout pages ensures that users cannot land directly on them from search engines, improving the user experience and protecting sensitive transaction information.
- User-generated and Sponsored Content: User-generated content, such as reviews, comments, or sponsored content, may be blocked to prevent low-quality or irrelevant content from appearing in search results.
- Media Files (Images, Videos): Media files are sometimes blocked from crawling to conserve bandwidth and reduce the visibility of proprietary content in search engines, ensuring that only relevant web pages appear in search results.
- APIs: APIs are typically blocked from crawling as they are intended for machine-to-machine communication, not search engine indexing. Blocking APIs helps prevent unnecessary server load caused by bots attempting to crawl them.
By blocking these types of pages and content through the robots.txt file, website owners can improve crawl efficiency, reduce duplicate content, and ensure that search engines focus on the most valuable pages for indexing.
Blocking “Bad” Bots
Bad bots are web crawlers that engage in harmful or unwanted activities, such as scraping content or, in more severe cases, attempting to find vulnerabilities to steal sensitive information.
Even bots that aren’t explicitly malicious can be considered "bad" if they overwhelm websites with excessive requests, leading to server overloads.
Additionally, some webmasters may want to block certain bots simply because they don't benefit from allowing them to crawl their site. For example, a website owner might choose to block Baidu if they don’t have a customer base in China, to avoid unnecessary requests that could impact server performance.
While some malicious bots may ignore the directives in a robots.txt file, many websites still use the file to block them. In fact, in the 60 robots.txt files analyzed, 100% of sites had rules that disallowed at least one user-agent from accessing any content on the site (using disallow: /).
Blocking AI Crawlers
Among the sites analyzed, GPTBot was the most commonly blocked crawler, with 23% of sites preventing it from crawling any content. A similar trend was observed by Originality.ai, which tracks the top 1,000 websites and found that 27% of these sites blocked GPTBot as of November 2024.
The reasons for blocking AI crawlers can vary widely, from concerns about data privacy and control to not wanting content used in AI training models without compensation.
Whether or not to block AI bots in the robots.txt file is a decision that should be made based on specific site needs and goals.
For websites that don’t want their content used in AI training but still wish to maintain visibility, there’s good news. OpenAI is transparent about how GPTBot and other crawlers are used. Sites should consider allowing OAI-SearchBot, which is used to display and link to content in SearchGPT, ChatGPT’s real-time search feature.
Blocking OAI-SearchBot is much less common, with only 2.9% of the top 1,000 sites choosing to block this particular crawler.
Getting Creative
The robots.txt file is not only essential for controlling how web crawlers access your site, but it also offers a unique opportunity to showcase a site’s creativity.
While reviewing over 60 robots.txt files, I stumbled upon some fun surprises, like playful illustrations hidden in the comments of Marriott and Cloudflare’s files.
For example, Marriott’s robots.txt file and Cloudflare’s file included delightful touches that make them stand out. Some companies even use their robots.txt files as creative recruitment tools.
TripAdvisor's robots.txt, for instance, cleverly doubles as a job posting in the comments section:
“If you’re sniffing around this file, and you’re not a robot, we’re looking to meet curious folks like yourself…
Run – don’t crawl – to apply to join TripAdvisor’s elite SEO team!”
So, if you’re on the lookout for a new career, browsing robots.txt files might be a fun alternative to LinkedIn.
How to Audit Your Robots.txt
Auditing your robots.txt file is an important part of technical SEO. A thorough audit ensures that the file is optimized to improve site visibility without accidentally blocking important pages.
To audit your robots.txt file:
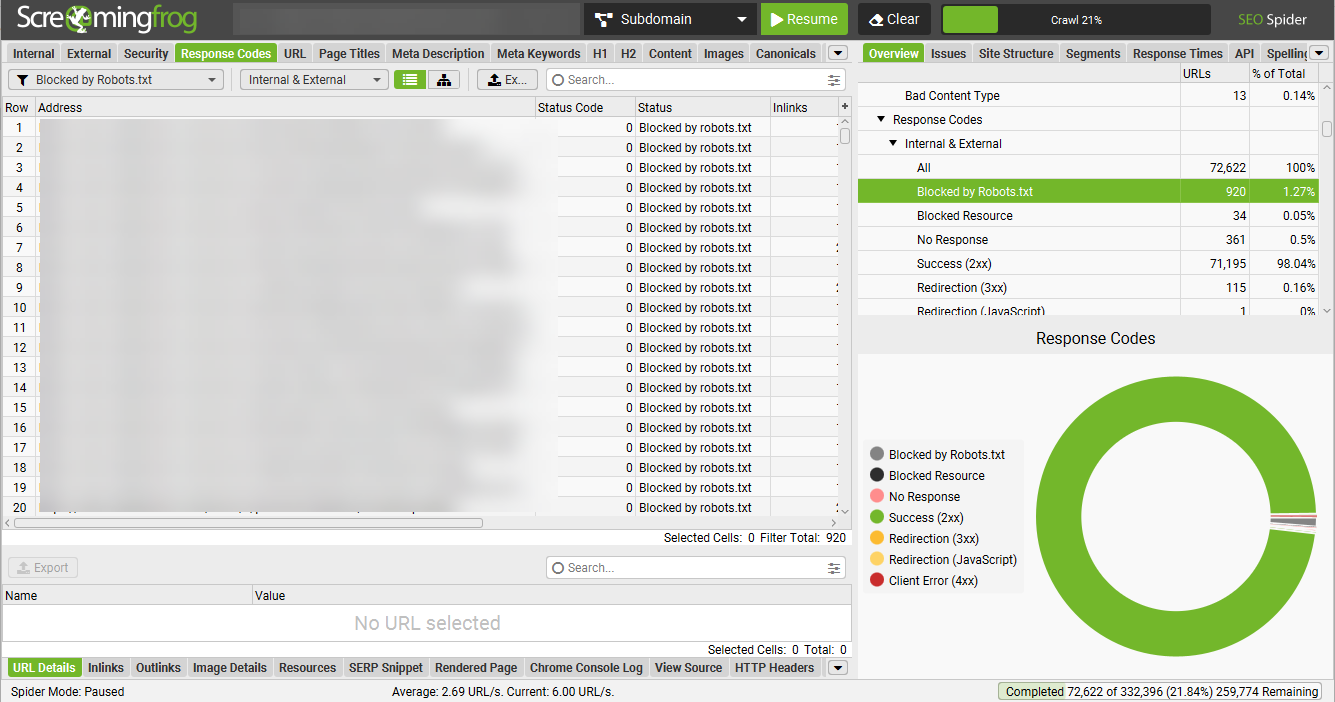
- Crawl the Site: Use your preferred web crawler (I like Screaming Frog, but any tool will work).
- Filter for Blocked Pages: Look for pages flagged as “blocked by robots.txt.” In Screaming Frog, this information can be found under the "Response Codes" tab, filtered by “Blocked by robots.txt.”
- Review Blocked URLs: Check the list of blocked URLs to see if they should really be restricted. Refer to common content types (like duplicate or low-value pages) to decide what should be blocked.
- Check the File: Open your robots.txt file and verify that it follows SEO best practices, avoiding common mistakes.
By following these steps, you can ensure your robots.txt file is both functional and creative, benefiting both your site's SEO and your team's personality.
Robots.txt Best Practices (And Pitfalls To Avoid)
The robots.txt file is a powerful tool when used properly, but there are common mistakes that can unintentionally harm your site’s SEO. Here are some best practices to follow in order to avoid blocking important content or causing other issues:
Create a robots.txt file for each subdomain: Each subdomain (e.g., blog.yoursite.com, shop.yoursite.com) should have its own robots.txt file. This allows you to set specific crawling rules for each subdomain, as search engines treat them as separate entities. A dedicated file for each ensures that you can manage which content is crawled or indexed on each subdomain.
Don’t block important pages: Ensure that essential pages, such as product or service pages, contact information, and blog posts, are accessible to search engines. Also, check that blocking certain pages isn’t preventing search engines from crawling other important pages linked to them.
Don’t block essential resources: Avoid blocking JavaScript (JS), CSS, or image files, as these are critical for search engines to properly render your site. Blocking them may prevent search engines from understanding your page layout or content.
Include a sitemap reference: Always link to your sitemap within your robots.txt file. This helps search engines locate and crawl your most important pages more efficiently.
Don’t restrict access to only specific bots: If you block all crawlers except for specific ones like Googlebot or Bingbot, you might accidentally block bots that could be beneficial to your site, such as:
- FacebookExternalHit – used for Open Graph protocol.
- GooglebotNews – used to index news content in Google Search and the Google News app.
- AdsBot-Google – used to check the quality of web ads.
Don’t block URLs you want removed from search results: Blocking a URL in robots.txt only prevents search engines from crawling it, but doesn’t remove it from the index if it’s already there. To completely remove a page from search results, use the “noindex” tag or URL removal tools.
Don’t block your entire site: Avoid blocking all search engines from crawling your entire site. Blocking all bots can severely limit your site’s visibility in search results and harm your SEO efforts.
By following these best practices, you can ensure that your robots.txt file is used effectively, helping to control search engine crawling without inadvertently blocking important content.
FAQ's
What is a robots.txt generator?
A robots. txt file tells search engine crawlers which URLs the crawler can access on your site. This is used mainly to avoid overloading your site with requests; it is not a mechanism for keeping a web page out of Google. To keep a web page out of Google, block indexing with noindex or password-protect the page.
Is robots.txt used anymore?
Some archival sites ignore robots. txt. The standard was used in the 1990s to mitigate server overload. In the 2020s, websites began denying bots that collect information for generative artificial intelligence.
Is robots.txt legal?
Yes, the robots. txt file is legal, but it is not a legally binding document. It is a widely accepted and standardized part of the Robots Exclusion Protocol (REP), which web crawlers and search engines use to follow website owner instructions about which parts of a site they can or cannot crawl.
What is an AI generator?
AI image generators utilize trained artificial neural networks to create images from scratch. These generators have the capacity to create original, realistic visuals based on textual input provided in natural language.
Are Android robots real?
Historically, androids existed only in the domain of science fiction and were frequently seen in film and television, but advances in robot technology have allowed the design of functional and realistic humanoid robots.





















0 Comments
No Comment Available